在訓練機器學習模型和深度學習模型時,有時碰到欠擬合(Underfitting)和過擬合(Overfitting)的情形,其中Overfitting相較於Underfitting更需注意。
下圖為兩類情形的示意圖,左圖為Underfitting的狀況,模型所訓練的結果為紅色線段,由於僅使用線性的模型來劃分類別,導致模型的表現極差;中間的圖為配適較為合適的模型;右邊為Overfitting的結果,此示意圖呈現了多數模型overfitting的情況,模型已經過度依賴訓練資料,產生了一個過於複雜的模型。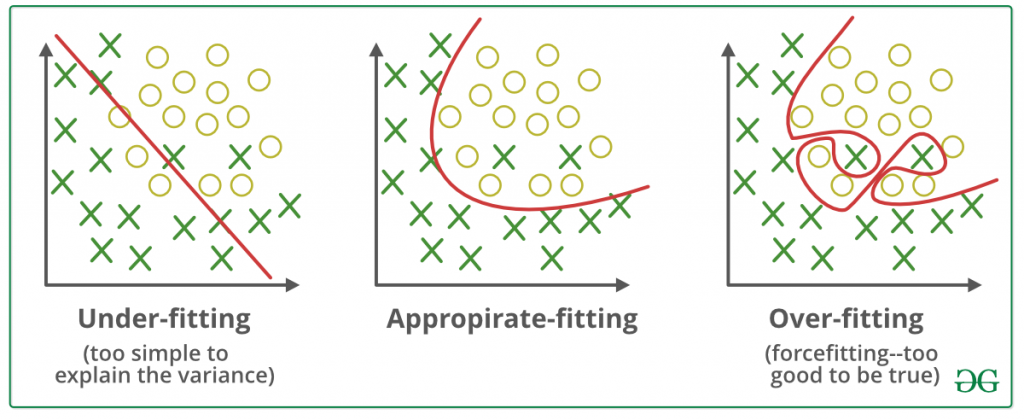
圖片來源:連結
相較於overfitting,underfitting的問題較容易處理。
當模型訓練時間過長、迭代次數過多時,常會有過擬合的問題,如何確認模型是否過擬合,則需要觀察訓練集的Error以及測試集的Error。當兩種Error的數值開始出現較大的差距時(如下圖),則模型可能已經o形verfitting了。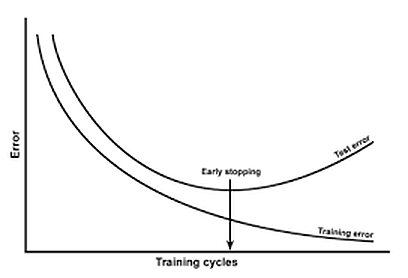
from keras.callbacks import EarlyStopping, ModelCheckpoint
## patience=10,但代表當測試資料集中的loss在經過10個epoch後都沒有下降,則會停止訓練
earlystop = EarlyStopping(monitor='test_loss', patience=10, verbose=1)
## 在callbacks中放入early stopping的設定
model.fit(x_train,y_train,batch_size=100,epochs=100, validation_data = (x_test, y_test),callbacks = [earlystop])
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras import regularizers
model = Sequential()
# 使用L2正規化
model.add(Dense(output_dim=200,activation='relu',kernel_regularizer=regularizers.l2(l=0.001)))
##lambda為正規化需要設定的超參數,若太小會導致懲罰項無用,若太大則會影響模型收斂的情形
model.add(Dropout(p=0.5)) # p會決定每個神經網路是否關閉的機率
# 使用L1正規化
model.add(Dense(output_dim=50,activation='relu',kernel_regularizer=regularizers.l1(0.001)))
在訓練模型時,需要留意模型是否有出現underfitting以及overfitting的問題,在使用上述幾個技巧後,仍需要多加注意,才能使模型能夠有更好的表現


 iThome鐵人賽
iThome鐵人賽